Genetic and biochemical challenges to the evolution of new genes – introduction
Preliminary comments
- Note that by ‘evolving’ I mean substantially new genes originating in an evolutionary way. There is some scope (though very limited) for genes, once available, to change in an evolutionary way, for example in the emergence of some forms of resistance to antibiotics and pesticides (see Evolution under the microscope pp 235-244).
- Although the issues considered here are also relevant to the origin of life, they are discussed here primarily in the context of what would be required for new genes to arise in the course of evolution – e.g. those needed for significant new structures or functions such as the origin of eukaryotes, meiosis, new body plans, organs such as eyes, various types of skeleton, feathers, or flowers.
- Also, the primary focus is genes that code for new proteins, although many of the issues also relate to other types of gene, e.g. those coding for RNAs.
- The comments on this page are introductory; follow the links for more details.
Overview
There are 4 stages to the case why it is prohibitively improbable (realistically impossible) for genes (for proteins) to arise in an evolutionary way:
1. Most proteins have a very specific (and hence highly improbable) amino acid sequence.
Proteins are linear sequences of amino acids. Typical short proteins are about 100 amino acids long (most are much longer); there are 20 different types of amino acid, any of which can theoretically be at any position in the sequence; so the number of possible sequences is truly astronomical (in fact much bigger than that!).
But, for almost all proteins, in order to function the sequence must be very specific (some variation in sequence is permissible, but this is strictly limited). What this means is that the number of sequences that might work is an infinitesimally tiny fraction of the theoretically possible number of sequences; i.e. realistically there is no hope of coming across a sequence that works by chance.
And of course the same is true of the nucleotide sequence (in DNA) coding for the protein.
Read more about the odds against new proteins.
2. Proteins could not have started off as short sequences.
The prima facie improbability of protein sequences has been known for a long time, and is accepted by most proponents of evolution. However, this improbability in itself is not enough of an objection, because of course proponents of evolution argue that proteins would not have arisen in one hugely improbable step, but would have evolved progressively, e.g. from shorter (even if less effective) sequences (for which of course there are fewer sequence possibilities, which would improve the odds of coming across a sequence that works). This is what evolutionary textbooks say (if they say anything about how new genes might have arisen), but a little investigation shows that there are substantial objections to this:
The two main reasons against proteins starting off as short sequences (or having done so) are:
2.1 Proteins need to fold, and this requires a minimum length of about 70 amino acids
Although proteins are linear sequences of amino acids, in order to have biological function they need to fold into a 3-dimensional shape.
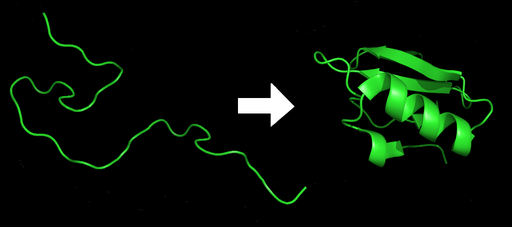
In biochemistry an unfolded amino acid sequence is called a polypeptide, only when it is folded is it called a protein. [a]
To be able to do this it needs to be possible to pack the amino acids very closely together – rather like a 3D jigsaw (while still being connected together in a linear sequence). The forces between the amino acids (holding them together) are very weak [1] and to have enough overall force to hold the protein in its folded state requires the protein to have a minimum of about 70 amino acids. [2]
This fact is generally completely ignored in speculative scenarios of how proteins might have evolved, with some textbooks even suggesting that proteins could have started off with just a handful of amino acids. [3] But that simply would not work.
Read more about protein folding.
2.2 Key amino acids are dispersed throughout the length of a protein's amino acid sequence.
In most proteins, key amino acids, such as those that contribute to an enzyme’s ‘active site’, are generally scattered throughout the linear amino acid sequence, and are brought together only once the protein has folded. For example, three amino acids involved in the active site of the digestive enzyme chymotrypisn are a histidine at position 57 in the sequence, aspartic acid at position 102, and serine at position 195. [4]
If proteins had evolved from short sequences, one would have expected that at least these critical amino acids (which must have been close together in a short protein) would still be grouped together. Because to disperse them during the course of subsequent evolution would require restructuring the protein, which would incur the same sort of improbability that the postulated short proteins are intended to overcome. (And bear in mind that the restructuring would need to have been effected in small steps, each with a reasonable chance of happening and offering some advantage that could be favoured by natural selection.)
3. Any evolution of a protein-coding sequence must be in association with other sequences that identify it as a gene.
The protein-coding sequence is only part of a gene. By itself, a stretch of DNA that (potentially) codes for a protein, will not result in the production of that protein. At the very least, for a stretch of DNA to be recognised as coding for a protein, at its ‘upstream’ end there has to be a particular (control) sequence to identify the following sequence as coding for a protein. (It will signal the protein-coding sequence to be transcribed into mRNA which will then be used to direct production of the protein.)
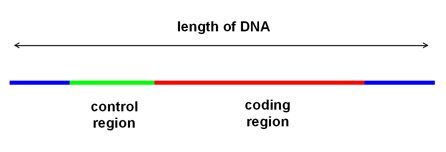
That is, even if a sequence that codes for a viable protein should arise, unless it has an upstream control sequence, the organism has no way of ‘knowing’ the coding sequence is (potentially) useful, so it is likely to degrade by mutation, and be lost. Similarly, a control sequence by itself has no utility unless it is followed by a protein-coding (or similarly useful) sequence, and is also likely to be lost.
Hence, because natural selection has no foresight (it cannot ‘see’ potential usefulness), both the control sequence and the protein-coding sequence must be viable: one without the other will not do. This means that even the most rudimentary of proteins requires an extraordinary coincidence of both sequences (protein-coding and control), arising independently, and yet being viable, and in the right order along the DNA, and probably not too far apart.
The above considerations:
- that short proteins will not fold,
- that key amino acids are dispersed throughout a protein’s amino acid sequence, and
- that a (potentially) protein-coding sequence is useless without being associated appropriately with other sequences that ensure it is recognised and used,
are plain to any with a reasonable knowledge of biochemistry. Yet they are almost never mentioned in evolutionary accounts of how proteins might have evolved. Is this just a blind spot (blinded by the presumed ‘truth’ of evolution), wishful thinking, or deliberately evading inconvenient facts?
Yet that is not all …
4. Most proteins are dependent on others for their activity / utility, which exponentially increases the odds against proteins evolving.
The problems against the evolution of any individual protein are compounded because most proteins do not act alone but are dependent on others.
So, for example, consider where two proteins are required for a particular function (and neither protein has any use by itself): If one protein were somehow to arise, because natural selection has no foresight, it cannot know its potential usefulness (when the second protein is also available); so the first protein will not be kept in reserve for the future, but its gene will be degraded by mutation, and lost. In other words, if a function requires two proteins then both must arise more-or-less together. Which, given the improbabilities against a single protein arising (see above), would require an incredible coincidence of extraordinary coincidences.
Most biological functions require many mutually dependent proteins, not just two; and the improbability of evolving such systems increases exponentially with each additional protein required. And note that whereas a single protein could arise more-or-less at any time and location provided it has utility, when two or more proteins are required for a particular function then they must both/all arise together – at more-or-less at the same time and place. What are the chances for that happening? It is this compounding of improbabilities that completely defies an evolutionary origin for new genes.
There are various ways in which proteins are mutually dependent on each other for their function / utility, notably in embryonic development which I shall expand on in due course. For now, a good example is the replication of DNA, especially because it illustrates the two-tier complexity of biological systems:
- the overall system is complex, necessarily requiring many components, and
- each of the individual components is complex.
Most if not all of the individual proteins considered separately are of a size and specificity that presents a formidable, probably insuperable, challenge for them to arise by chance. So it just is not credible that a combination of such mutually dependent proteins could arise more-or-less together (spatially and temporally) – which is what would be required for a process guided by natural selection. The more we find out about how biological systems function at the molecular level, the clearer it is that such systems could not have arisen by a merely opportunistic evolutionary process.
Notes
Notes display in the main text when the cursor is on the Note number.
1. Mainly what is called the hydrophobic effect.
2. Jack Kyte, Structure in Protein Chemistry, Garland Publishing (1995) p243.
3. For example, see Monroe Strickberger, Evolution, Jones and Bartlett (1996), p61.
4. Wikipedia article: chymotrypsin https://en.wikipedia.org/wiki/Chymotrypsin
Image credits
Graphics are by David Swift unless otherwise stated.
Background image for the page banner is from https://commons.wikimedia.org/wiki/File:How_proteins_are_made_NSF.jpg and is in the Public Domain.
a. Image by No machine-readable author provided. DrKjaergaard assumed (based on copyright claims). [Public domain], via Wikimedia Commons; from https://commons.wikimedia.org/wiki/File:Protein_folding.png
Page created March 2017; last modified December 2018.